十年前,我在微软研究院语音组混日子。混,不是我的主观意愿,却是客观事实:当时,我们做的“人机交互”离实用太远,别人都认为我们是编了个故事来骗工资的。有一回,跟同学聊起我们的愿景:“将来,您对着电脑,乐意怎么说怎么说,那边不光嗯啊嗻是,有来言就有去语,回答的还得像话…”正说着,他乐成桃状打断了我:“你说的这不是跳大神,让狐仙附了体了么?”
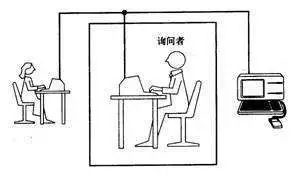
这当然是戏言,因为建国以后就不许成精了。觉得这事儿扯的,要怨您就怨一位前辈的老先生——图灵。是怹在人工智能八字还没一撇的时候,提出了这个终极测试方案:将人与机器隔开,前者通过一些装置(如键盘)向后者随意提问。多次问答后,如果有超过30%的人不能确定出被测试者是人还是机器,那么这台机器就通过了测试,并被认为具有人类智能。
于是,通过图灵测试,就成了所有人工智能科学家和伪科学家的最高目标。这两年人工智能大火,号称通过了图灵测试的产品,也如雨后春笋般一抬脚踩死一片。最近的一次,是谷歌在I/O大会上演示的Deplux,据说“部分通过图灵测试”,这倒还算中肯。
看起来,图灵的棺材板快压不住了,我们是否已经到了突破图灵测试的奇点了呢?我正在一头雾水之际,突然有天晚上,黑暗暗雾沉沉,图爷托兆给我,对我言道:“这事儿,还离着六扔(见注1)多远呐!现传尔秘籍一部,望尔潜心习学,授众生以三法门!”你道哪三个法门?且看下文分解。
图灵测试是不是人机“对话”?
理解概念,要把握其内涵和外延。图灵测试的内涵很清楚,就是用机器替代人,进行信息交互;不过其外延有些不清,颇多可变通之处,比如那个“一些装置”。时下的相关产品,交互或用文字,或用语音,对于信息沟通来说,这样的装置够用么?
我们知道,对人类来说,文字仅仅承载着内容的沟通。而人人信息交互,内容沟通大概只占20%,情感沟通要占到80%。计算广告群里的九千岁讲了个生动的例子:当年他给女朋友打电话,信息量最大的,就是对方拿起电话那一声“喂”,这个“喂”就为今天几个钟头的会谈定下了基调。
情感沟通,要理解的就不仅仅是文字,还包括语音、表情、肢体语言等等。所以,两个在知乎上吵得不可开交的人,打个电话没准就成了基友;而真正重要的面试、会议,还是必须面对面进行。没有对这些副语言现象深入的研究建模,即使完美地解决了文字和内容沟通的问题,也离真正有效的人机交互相去甚远。

因此,人机“交互”绝非人机“对话”,我认为真正理想的图灵测试,就算不能声情并茂地反馈用户,也至少应该能察言观色,有效解读用户的副语言。将来用上机器女友了,人家“喂”了一声,你还不知道怎么接下碴儿,那还不等着回家跪电路板?
显然,这样去限定图灵测试的话,我们现在仍然束手无策。饭要一口口吃,先降低下难度,仅仅考虑利用文本或语音跟机器聊天的场景,我们今天看到的Siri、小冰、Alexa、叮咚音箱等,都是这样的人机对话系统。那么,是否在人机“对话”的情形下,通过图灵测试已经指日可待了呢?
既然不用理解副语言现象,人机对话的关键,当然就是理解自然语言了。自然语言理解和人机对话,是认知智能领域的核心问题,要了解它遇到的困难,要先从目前人工智能的实用方法说起。
人机对话,到底难在哪里?
今天所有实用的人工智能产品,都是用的“弱智”(见注2)方法。简单来说,就是凑答案:准备一大坨标注好的数据,然后用大量机器堆上去狂撩,直到把答案凑个八九不离十。至于问题的内在逻辑和简约规律,今天的AI既无心顾及,也无力解读。
“弱智”方法在数据充沛的领域,可谓所向披靡:无论是语音识别、人脸识别,还是机器翻译、各种棋类,机器都已经接近乃至碾压真人了。且慢!机器翻译都快解决了么?翻译可比聊天要难吧?不然,机器翻译这个问题,答案是比较好凑的:找到足够多的语言对数据,把词译过去跟麻将牌一样码好了,再调整一下顺序即可。人机对话则不然,我们要找到对方语言里的关键信息,把它转化为动作,再把动作的结果反馈回去。这些关键信息处理的过程,是要经过统计意义上的推理过程的。
说到推理,当然离不开句子表达内容以外的背景知识。比如你问机器:“直径为10的球体积是多少?”机器就得会球的体积公式才算得出来。当然,微积分、背古诗、查法典这样的知识,对机器来说总是可以解决,因为有大量书本上的语料可供学习,按照弱智大法凑答案即可。难就难在,这世界上还有大量的知识,根本没地方学去。
直觉上,人的知识来自于六岁以后的学习。实际上,绝大部分知识都来自于六岁前神奇的积累过程。只不过,这些知识太普通了,连半傻子都知道,所以被大家都选择性地遗忘了。这种人人皆知的事情,姑且把它叫做“常识”,举两个例子您就明白了:
小明面对着你 =>
你瞧不见小明的后脑勺
一瓶矿泉水被我喝完了 =>
瓶子变轻了
就这个呀?这玩意也算知识?您别拿村长不当干部,没有这些常识的支撑,自然语言推理是进行不下去的,不信您看看下面这两句:
爸爸快抱不动儿子了,因为他太胖了
爸爸快抱不动儿子了,因为他太虚弱了
后半句的这个“他”,在上下两句指代的对象是不同的。显然,没有常识的支撑,这两句不好理解。悲催之处在于,这些常识,在所有人类积累的语料当中,是不存在的。您想想,有人要编纂一本专著,里面写的全是这样的“深奥”知识:
有孤王坐金殿脊背朝后
头冲上脚冲下脸冲前头
走三步退三步如同没走
两只手伸出来十个指头
那读者还不得骂着街把作者押送到精神病院啊?对此,郭德纲老师和其它曲艺界同仁给了个专业术语,叫“大实话”。

没有了语料、也就是数据的支撑,“弱智”方法是没办法获取这些常识的。所以,甭管谁说他的对话系统通过了图灵测试,你也别问它化学方程,也别让它背诵古文,就找几个这样的真・弱智问题问上一问,它要能答出来我是茄子。
那么人类的常识在六岁前是怎么获得的呢?对于这样的学术问题,我只能严肃地回答你:问村长去!
人机交互要不要模仿人人交互?
看起来,我们离通过图灵测试,还真有六扔多远。那么,从应用的角度看,人机交互这件事真的遥不可及么?这倒也未必。
从开始探索人机交互,我们就想当然地认为,把人人交互的那一端由人变成机器,就是人机交互的理想模式了。于是,我们设计出来的机器人,也都是俩肩膀扛个脑袋,四肢五官齐备,用语言的方式跟对面的人类交流,再加上对常识一窍不通,怎么看怎么像个二傻子。
问题出在哪儿了呢?人类的信息交互,最高效的输出方式是“说”,也就是音频通道;最高效的输入方式是“看”,也就是视频通道。如果你对面是个真人,那没办法,双方都只能靠说输出信息,这就形成了语音为主的交互方式。而靠语音的人机对话,是这样的画风:
我想订一张明天去上海的机票
为您查到:6:35海南航空HU7611,票价480元;6:50吉祥航空HO252,438元;6:50厦门航空MF8178,票价…
我去你大爷的吧!
别乐,就算对面不是机器是个真人客服,这种交互也同样令人抓狂,有过电话订票经历的朋友都有体会,只不过对着活人您不好意思骂街罢了。
既然对面是个机器人,就没必要如此拘泥了。实际上,机器的交互方式,应该跟我们“相反”而不是“相同”:你输出信息靠说,机器人接受信息就得靠听,这没错;你输入信息靠看,那机器人输出就别靠说了,何不在一块屏上展示出来呢?这样,不但信息输出效率提高了很多,而且用户只要在展示的信息底板上做选择题,就算用语音输入也大为便捷。
所以,真正适合人机交互的机器人,最好有个视频输出的设备,近了靠手机就可以,远了怎么办还值得探讨。这个概念,就是讯飞的胡郁老师讲的“强视觉呈现的语音交互”吧。这种模式下的交互方式,已经跟人人交互有了质的区别,未知之处很多,需要我们深入探索。当然,可以确定的是,机器人绝对应该抛弃人形,以避免用户用人的眼光和标准来评价它。

人机交互这件事,看起来简单,却是人工智能王冠上最耀眼的一颗明珠。目前看来,严格意义上的图灵测试离我们还相当遥远,不过通过交互方式和产品上的创新,一个在特定领域内可用的合格助手,或许已经在向我们招手了。
另外,由于计算机对海量信息的检索和处理能力远胜人类,或许可以让机器助手辅助人人交互,这样既能大大提高内容沟通效率,又能发挥人的情感沟通优势,这没准是目前更加可行的产品路线。
标签: